Digital editions survival kit
Reconstructing an edition
Computer systems are not meant to last, to the contrary - not only do they require regular maintenance but we need to take into account the unavoidable cycle of major refurbishments. This paper, just presented at the virtual TEI conference, aims to demonstrate how critically important aspects of an edition can be reconstructed from a rather minimal data set and how such a survival kit can be useful not only for disaster recovery but also as a sustainable approach for the maintenance of scholarly publications.

The following schemata are the key components of the survival kit:
- Source documents
- Document encoding and transformation scheme
- Layout templates
- Interoperable metadata mapping specification
TEI is the perfect archival format for text-centric data: human readable and easy to process - as long as we have the capacity to read text files we can recover the information from a repository of TEI texts. TEI encoded documents with an associated ODD schema and documentation already form a solid basis for reconstruction even if the ODD would say nothing about the final form of the publication as intended by the editors.

The TEI Processing Model covers part of this territory, describing how a source document should be transformed for publication. Nevertheless, in the virtual realm, the document is always accompanied by a certain context on the page: controls to zoom in or out, facing facsimile image or switch between normalized and original spellings, just to name a few options. To explicitly define such a context and specify how a publication page would look and behave we can rely on HTML5 layout templates. A modern, web components based approach to website design gives us a beautifully simple and expressive method of assembling web pages from a virtual Lego block equivalent.
The last missing piece is to document how abstract concepts, e.g. author or date of creation are realized in the encoding so we can recover and use them for queries within the publication as well as for data interchange with other systems. Given the richness of TEI it’s impossible to prescribe what metadata needs to be gathered and how exactly it should be encoded in any given project. On the other hand, it is rather simple to express the mapping in XML, e.g. with an index configuration syntax.
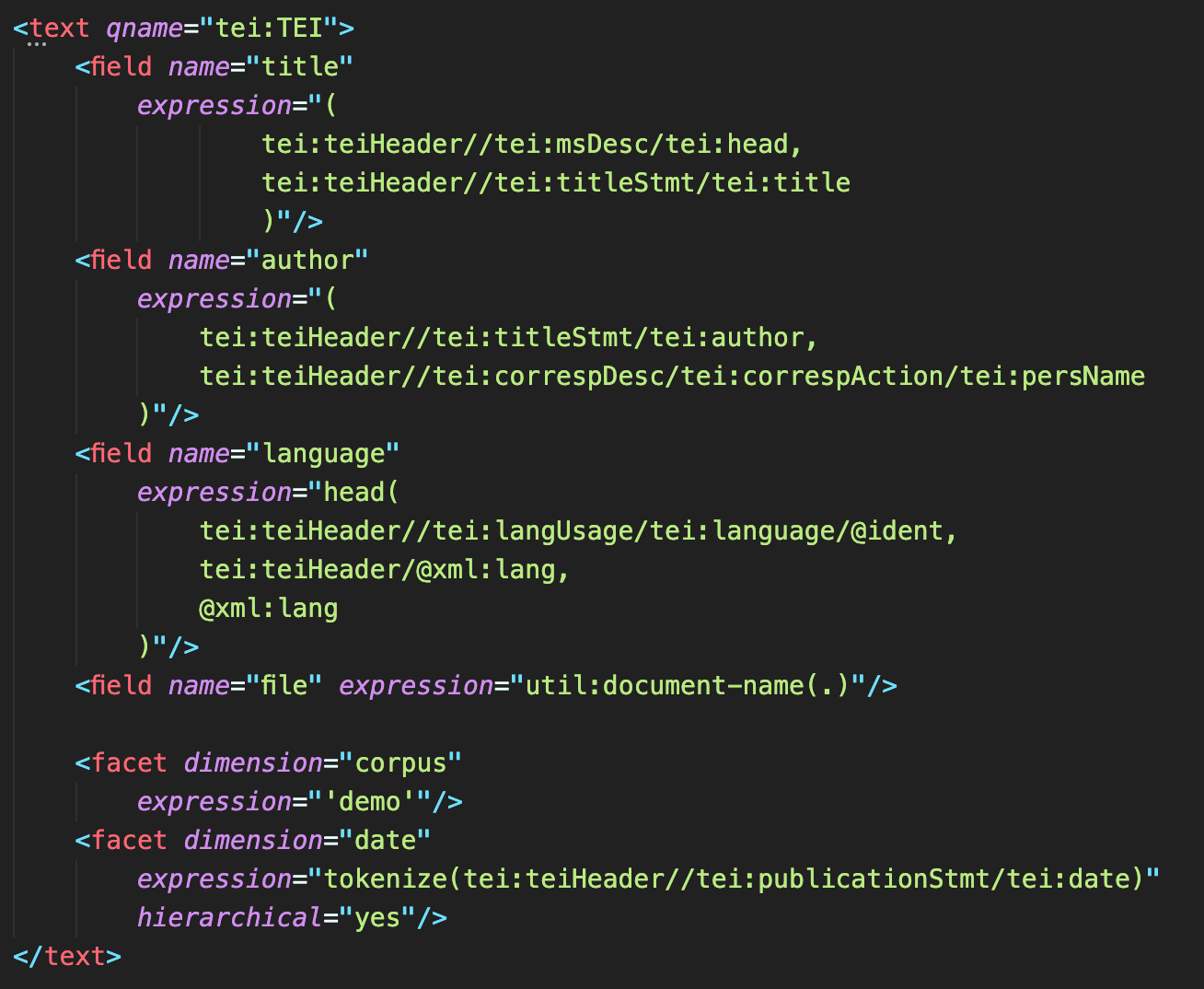
Such a set of specifications preserves all the information necessary to rebuild the edition from scratch, focusing on the intentions and decisions of the editor while filtering out the ephemeral or secondary presentation aspects. Good to put in the vault and send into space but equally useful when the time to migrate to a new infrastructure comes.

How does it work in practice? You might want to have a closer look at one of the TEI Publisher's demo apps When the Wall came Down which we managed to recreate on the basis of TEI sources and accompanying ODD released by Dodis on the 30th anniversary of the Fall of the Berlin Wall. We managed to get a draft version in only 165 lines of custom code and during just one day of pre-conference workshop. Our task would be still simpler if we also had the web page template and index configuration available.

Given that there's barely an extra effort involved in assembling the survival kit, preparing it is a clear win. After all, we already have the sources and the ODD! Enriching it with a processing model is not particularly difficult, especially if we use it to generate our transformations. Similarly, in most database systems we will need to prepare the index configurations. At this point we probably don't need to mention that TEI Publisher already implements this approach since quite a few versions (ODD with the processing model from inception, web components for user interface since version 4 and fields and facets since version 5).
Just think about it, if you pack your edition nicely, it becomes a present which archives and libraries would very much like to keep safe in their vaults and running on their servers forever...