Names sell: Named entity recognition in TEI Publisher
TEI Publisher 8 will include experimental support for detecting and tagging named entities in texts. The idea is to further simplify the work of editors when annotating documents via TEI Publisher’s web-based annotation editor by automatically identifying potential candidates for people, places etc.

If you have the development branch (or future TEI Publisher 8) installed and the named entity recognition (NER) service running (more on this below), an additional button will be shown in the top left toolbar. Clicking on it gives you a choice of NER models to use. By default those are the standard models provided by the NER engine we're using. Below we see NER in action, detecting entities in a modern-language text copied from wikipedia.
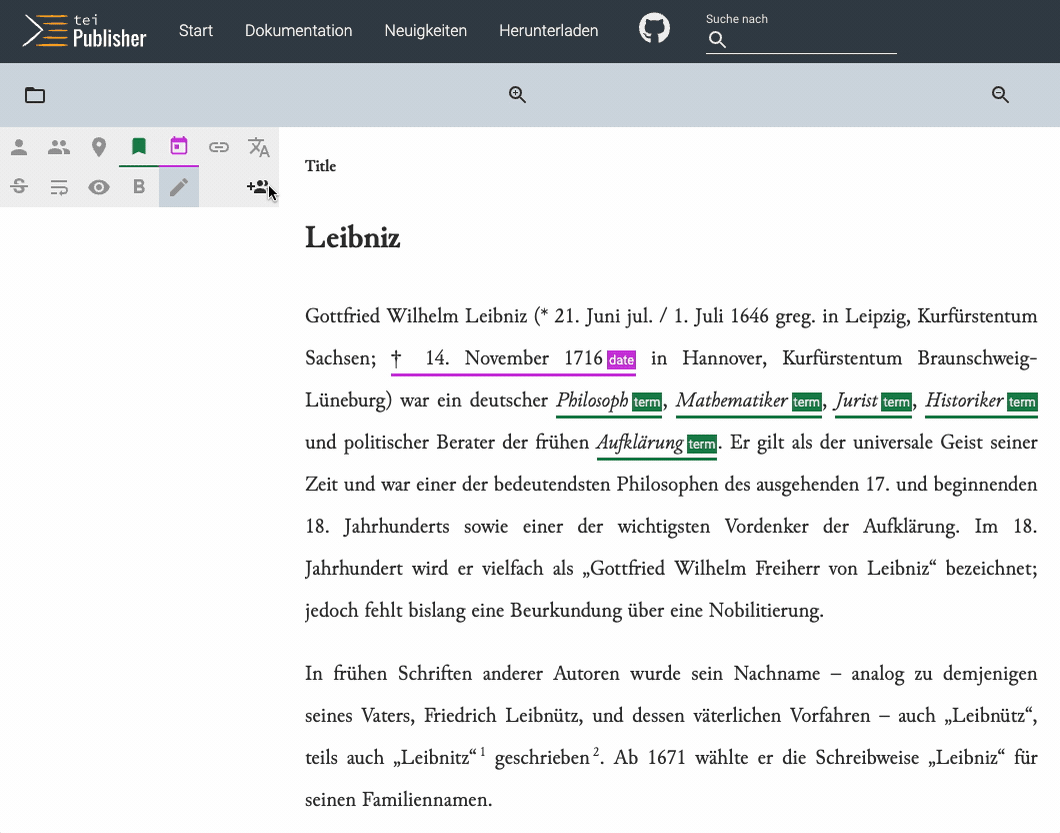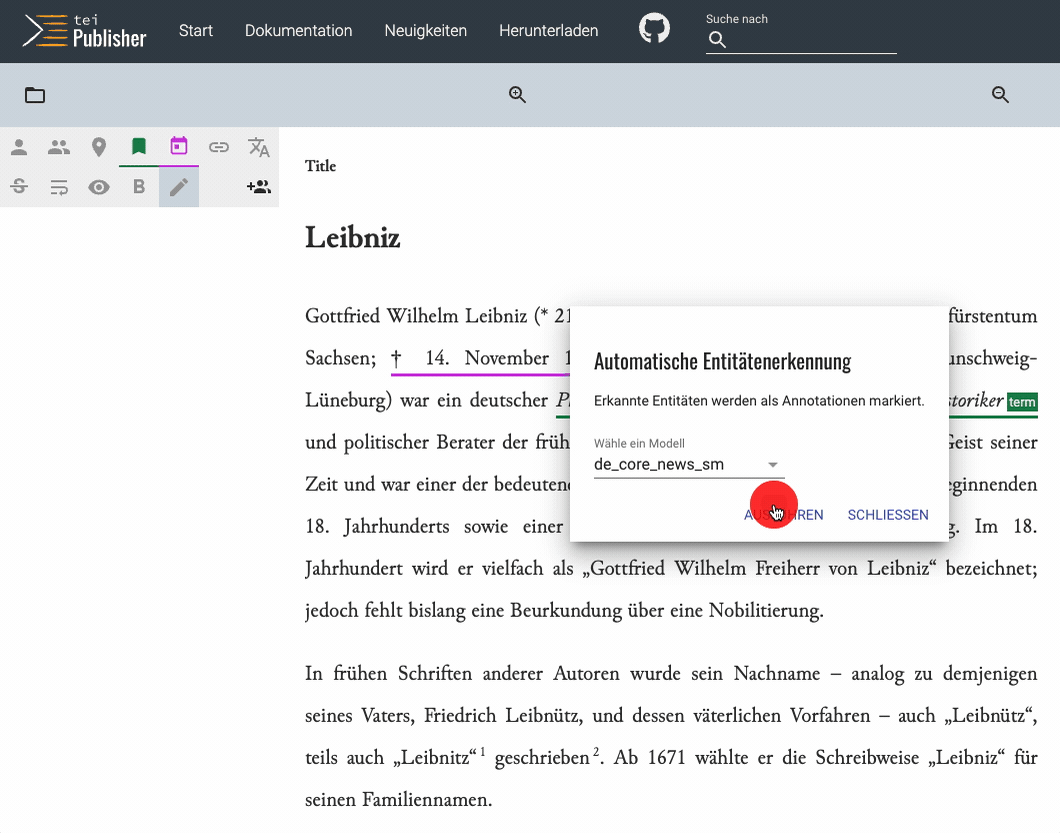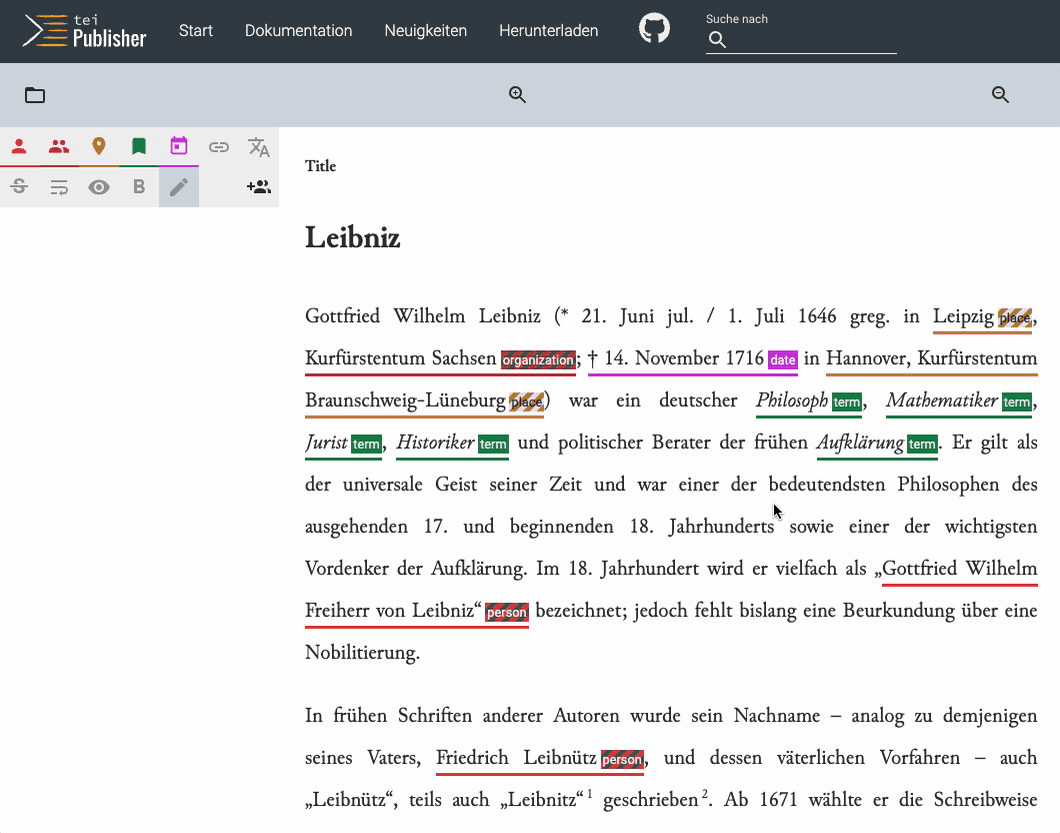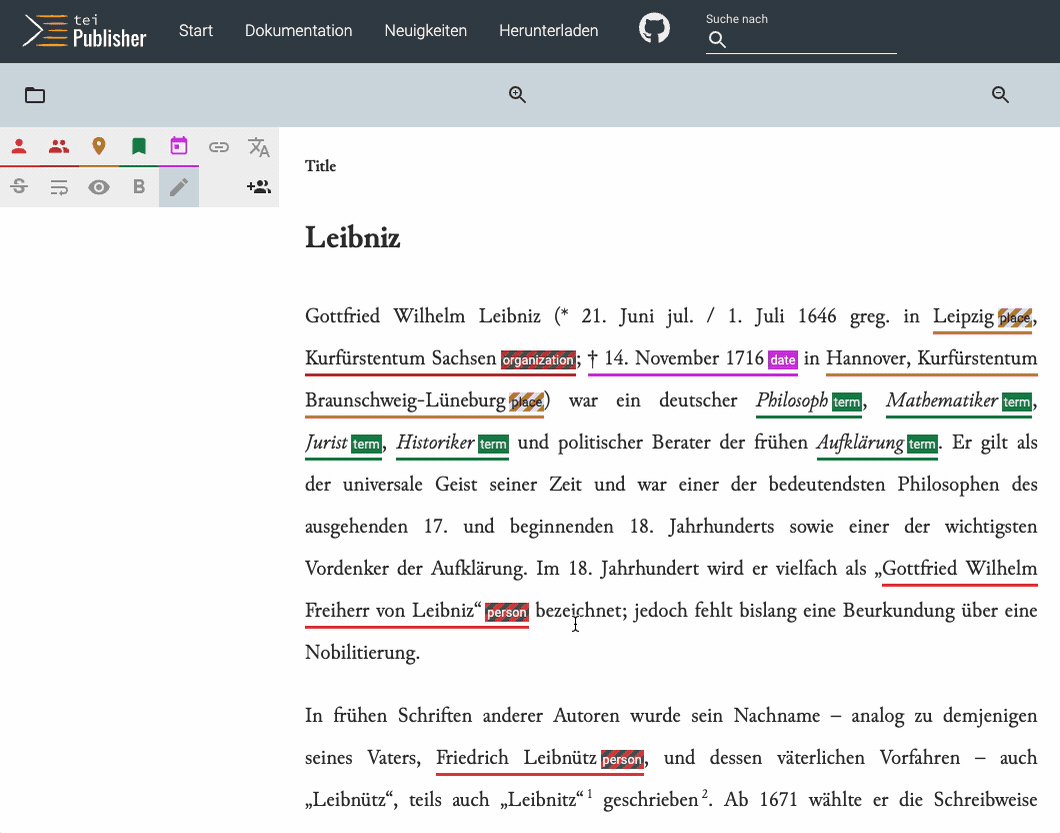
Entities identified by NER get a marker in striped color, which allows users to distinguish them from annotations, which were manually tagged. The user can now review the identified entities, assign them an authority entry etc. As each annotation is reviewed, the stripes will be removed.
While NER works well in this case on a modern language text, you'll soon encounter the limits of the standard model when trying it out on different types of literature. However, we can gradually improve the quality of the entity recognition by feeding completely annotated documents back into the process, i.e. train our own recognition model. The ideal workflow could be imagined as follows:
- editors manually tag a portion of documents via web-based annotations
- once a certain number of entities has been tagged, we can train a custom model
- continuing the annotation process, the custom model can be used to identify potential candidates for semantic annotations, thus improving the workflow
- the model is retrained on the growing set of fully annotated documents, resulting in better prediction rates
The ultimate goal is to make this process as smooth as possible, i.e. it should not hinder your editing work, but support it!
The integration in TEI Publisher is completely functional, but we need more testing, experimenting and kicking the tires with some real-world use cases. NLP is not a simple subject and I’m in no way an expert, so I’d like to invite the community to help. I have just prepared the ground work.
Technical Background
There are plenty of NLP and NER libraries and tools. However, such libraries work on plain text, not structured texts like TEI. They will get confused by angle brackets (just like many humans). The trick thus is to transform the XML into a plain text without loosing context, which means we somehow need to keep track of element boundaries, offsets of inline elements etc.
Likewise, the result of running NER is again a plain text document, accompanied by a list of detected entities and character offsets. Those need to be mapped back onto the XML structure and eventually merged into the TEI. This back-and-forth conversion is the main job handled by TEI Publisher and its API.
My first idea was to integrate another, existing command-line tool for enriching TEI with named entities. But after a few first experiments, it occurred to me that TEI Publisher already had some important bits and pieces in place within the annotation framework:
- it defines a standoff JSON format to keep annotations separate from the TEI as long as the user is making changes. The web-based editor reads this format to display the nice fruit salad - i.e. marked entities - you see on screen.
- it implements algorithms to merge the standoff annotations into inline TEI elements. This works loss-less: anything which is not an annotation is left untouched. The merge algorithm is fast and reliable.
We could thus reuse those building blocks and just add a communication layer, which mediates between TEI Publisher and the external NLP library. This communication layer has been realized through a set of Open API endpoints on both sides, allowing them to have a conversation, sending data back and forth. Below you see the NLP API endpoints exposed by TEI Publisher:
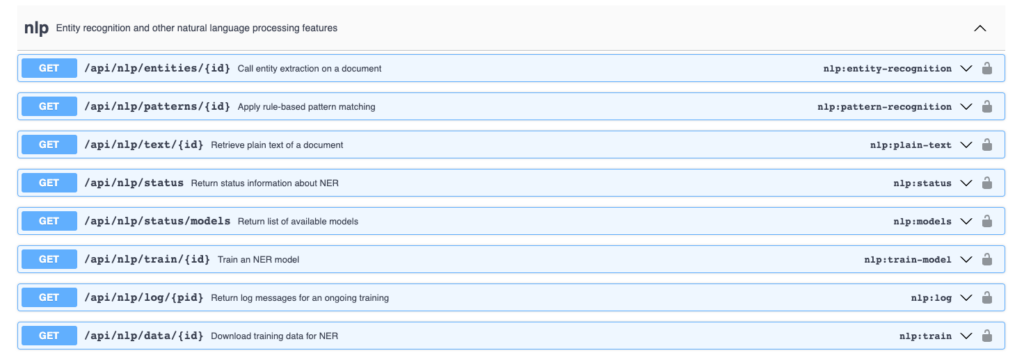
The NLP part is a python service using spaCy as the underlying NLP library. Compared to many NLP libraries I have seen before, spaCy has a rather simple, clean API. Getting started proved to be smooth and painless as most of the functionality comes pre-configured and ready to be used. A Python notebook demonstrating how to do a simple NER with spaCy is shown below:
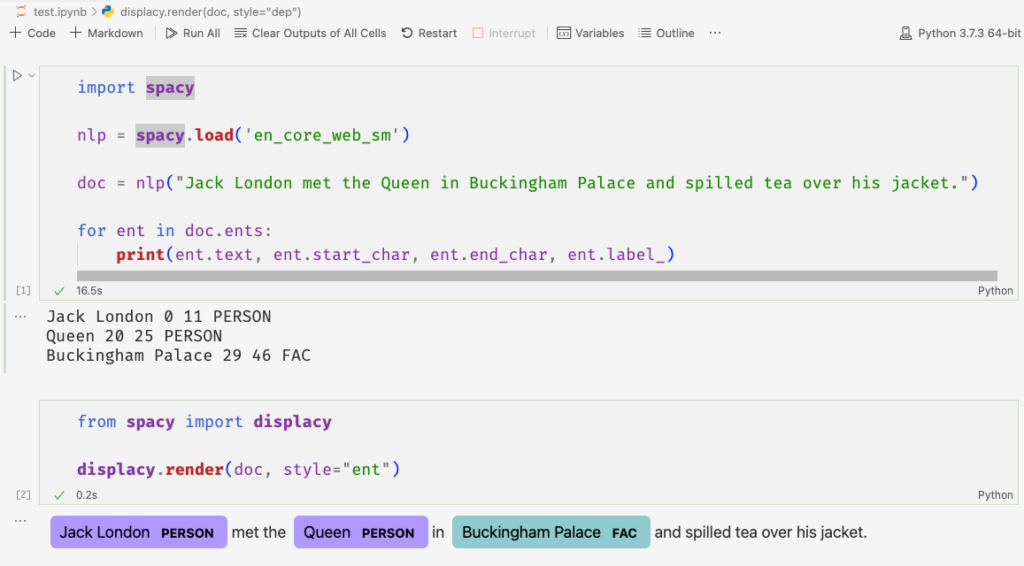
SpaCy can do more than just NER, e.g. part-of-speech tagging, dependency parsing, sentence segmentation, text classification, lemmatization, morphological analysis. It is also quite extensible, allowing other libraries to be plugged into its pipelines.
Training a model
Whenever you use a general-purpose NER model, you’ll quickly notice that it works great for some types of texts, i.e. texts similar to the ones it was trained on. However, results quickly degrade if you apply it to other genres or texts written in a slightly different period of time. For example, the German standard model in spaCy produces good results when run on a text from Wikipedia, but it already starts missing things when you apply it to letters written in the first half of the 20th century: the language used back then was just different, some would say: more sophisticated, than the language used today.
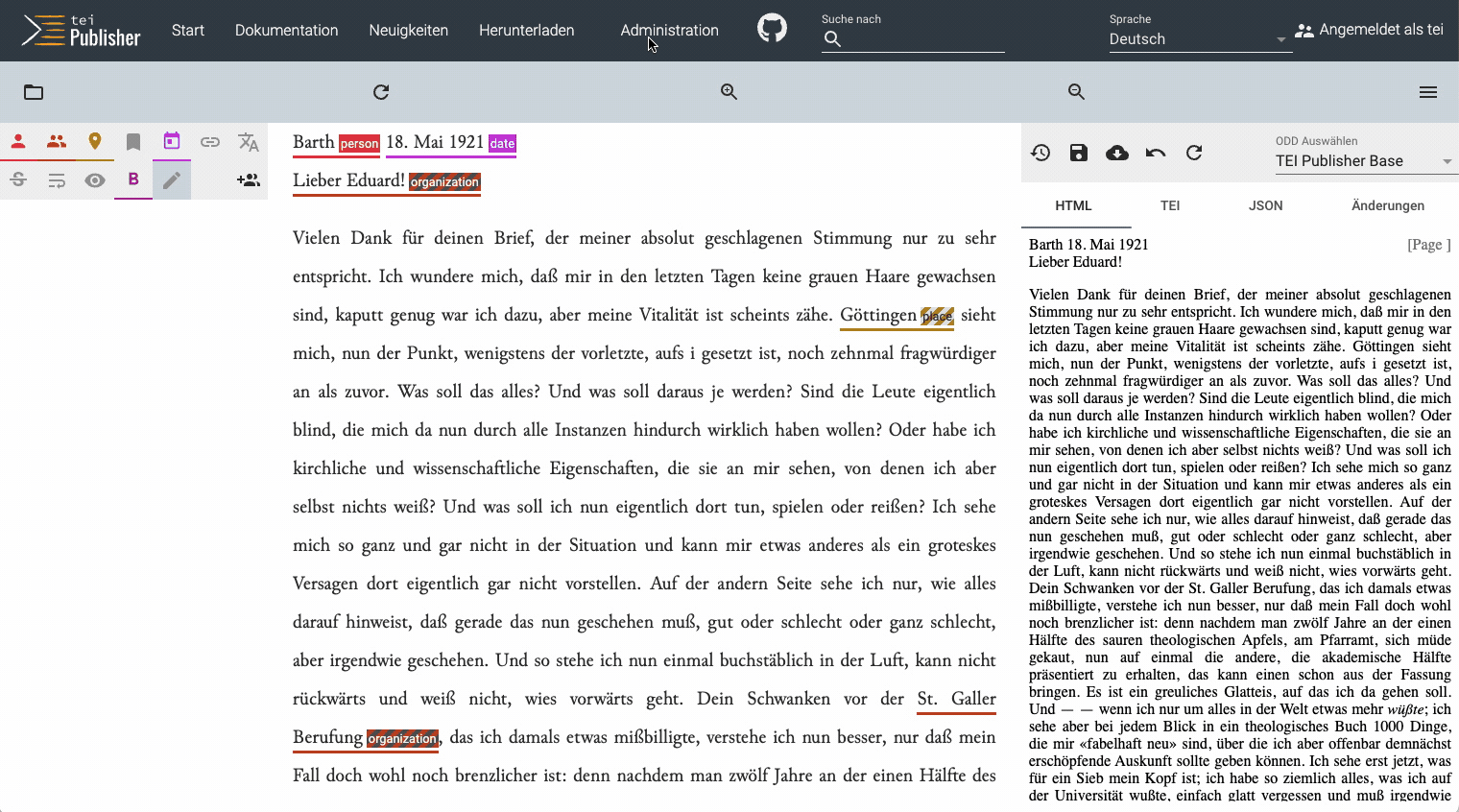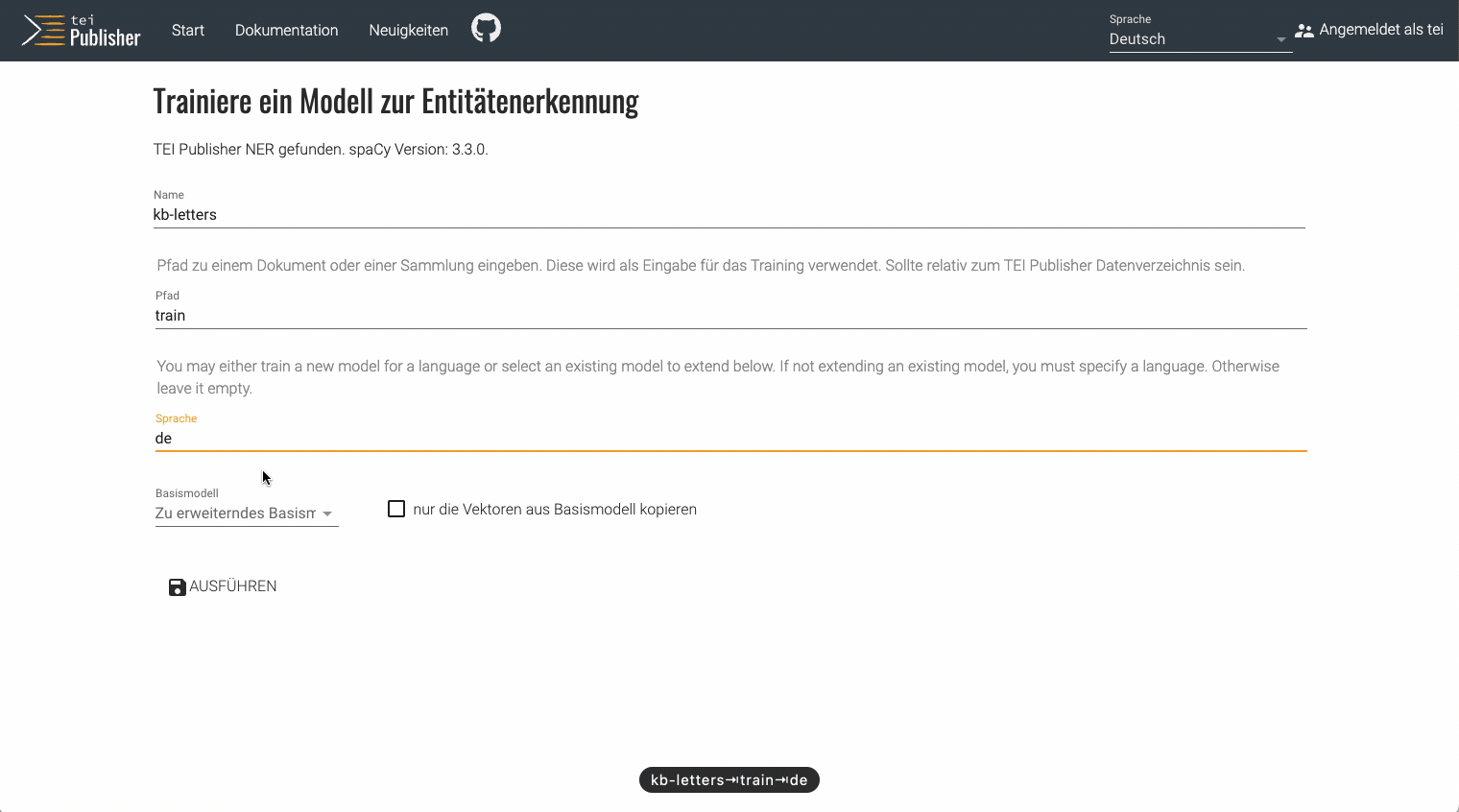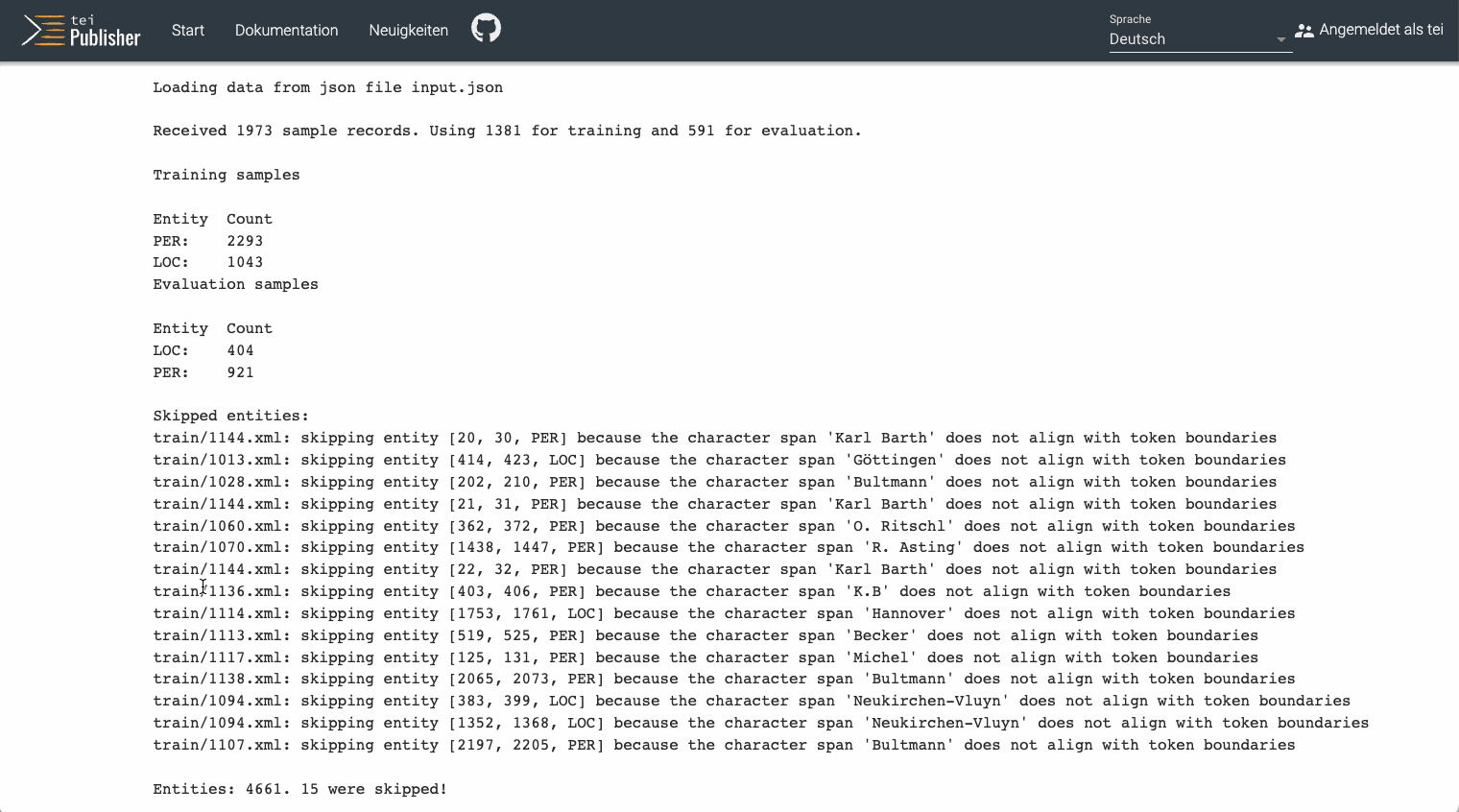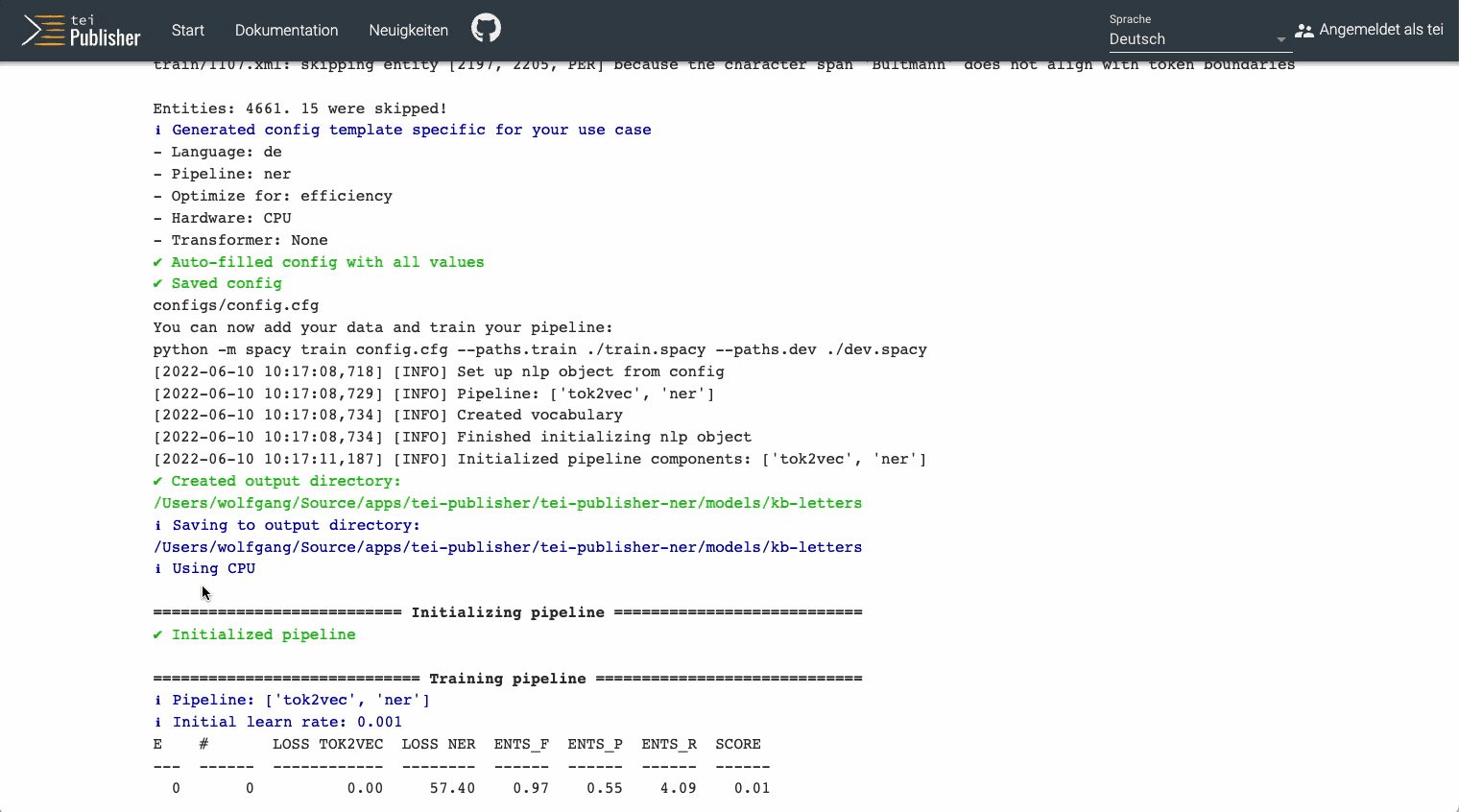
For example, if we run the standard German model against a letter by theologian Karl Barth written in 1921, many words are wrongly identified as places:

For most real world scenarios, there’s thus no way around training your own custom model. Fortunately this fits rather well into the annotation workflow implemented by TEI Publisher: usually, training a model involves going through a large amount of text to tell the NLP engine which words are considered part of an entity and which are not. Sometimes this is done in tabular form - which is quite tedious, but there are also tools to support the task, e.g. Prodigy, a commercial application created by the makers of spaCy.
All those approaches have one disadvantage: you do all the hard work just for the purpose of training a model. Compared to this, enriching the TEI with entities is a useful task in itself. Even if you figure out later that you can’t really use NER, the work invested is not lost. TEI Publisher tries to make this as seamless as possible, being able to transform any semantically rich TEI into training data. Preparing training data is thus kind of a natural side effect of annotating documents and does not require additional manual steps or separate tagging.
TEI Publisher exposes an API endpoint through which you can download training data in JSON format for either a single document or a whole collection.
It chunks the text into blocks (paragraphs, headings etc.) and extracts a plain text representation of each. Here it is important that sentences are preserved semantically. Inline notes, apps or choices would appear out of context in the middle of a sentence, so they have to be removed. Notes will be moved into separate blocks at the end.
All existing entities in a block, i.e. persName, placeName etc., are listed along with the text, recording their type, start and end positions:
{
"source": "train/1006.xml",
"text": " Bultmann Marburg, 25.V.1922 Lieber Herr Barth! ",
"entities": [
[
10,
17,
"LOC"
],
[
41,
46,
"PER"
]
]
}The exposed API endpoint is used by the python service running spaCy to retrieve the training data. The service will normalize the data, e.g. collapse whitespace, and initiate the training. By default, 30% of the sample records will be reserved for validating the model, 70% are fed into the training. Once completed, the resulting model will become available in spaCy as a new model to be used for entity extraction.
The actual training can be triggered in two ways:
- via a web page in TEI Publisher, which calls the python service, passing it the information you entered in a form
- via a separate python/spaCy project
We strongly recommend the 2nd approach as it gives you more control over the process and its configuration. For simple tests, the web-based form is sufficient though.
You can train a model from any collection residing below TEI Publisher’s data collection or the corresponding data collection of any custom application generated by TEI Publisher 8. For example, for the Karl Barth edition we already have several volumes of letters, which were manually enriched with entities via the web-based annotation editor. For a quick test, we can thus upload one volume of annotated letters to the train/ subcollection below TEI Publisher's data root (using eXide) and start training a custom NER model on this collection via the web interface:
The training will take a short while as it does several runs trying to improve accuracy. During the process, key figures are shown for each run and you should see how they gradually improve until a certain threshold is reached and the training stops.
Afterwards the new trained model will become available within the annotation editor and we can try NER on the same letter as before using the custom model:

Looking at the same passage of Barth's letter, we see that now only Göttingen is identified as a place. The wrongly detected places are gone. This is clearly an improvement over the standard model. The one name in the fragment, Nelly, is still not identified as a person, but the size of the training set was still rather small. The more documents we annotate, the more training data we have, and the quality of the model should gradually improve over time.
Running the NER service
For named entity recognition to be available in the web-based annotation editor, a separate Python service is needed: clone the tei-publisher-ner repository and follow the instructions in the README.
The tei-publisher-ner package uses spaCy’s own project configuration library, which in itself is quite a useful tool. The main configuration is contained in project.yml, which exposes a number of commands. You can also use those to train a custom model as an alternative to the web form we saw above. This gives you more control and more options.
To train a custom model you can either change the variables in project.yml or pass them as command line parameters, e.g.:
python3 -m spacy project run all . --vars.name=hsg_demo --vars.app_name=hsg-annotate --vars.training_collection=frus1981-88v05 --vars.lang=enThis will contact a TEI Publisher generated app called hsg-annotateand retrieve training data from the frus1981-88v05 collection below the app's data root, using English as the training language. The output of the command will pretty much look the same as the output you saw on the web before.
Conclusion
Even in its current, rudimentary form, the NER integration in TEI Publisher can already help to speed up the editing workflow. We do need to gain more experience with training custom models though and the community is warmly invited to help with this.
There’s also a lot of room for improving the annotation workflow, e.g. with
- automatically linking detected entities to authority entries (where non-ambiguous)
- implement a wizard-like dialog, which walks users through the entities identified by NER one by one, allowing them to quickly confirm or reject an annotation and associate it with the correct authority entry
- employ rule-based detection models in addition to the statistical, trained models: for example, if you already have a list of names from a back of book index, a rule-based algorithm may produce better results than a trained model
- support batch operation across multiple documents
- integrate other spaCy features like part-of-speech tagging etc.